
Nos últimos anos, a adoção de bancos de dados NoSQL, como o MongoDB, tem aumentado de maneira expressiva. Muitos chegam a falar que é o fim da linha para os bancos de dados relacionais, como o MySQL, PostgreSQL, SQL Server, etc. Mas será que é isso mesmo?
A resposta depende de uma série de fatores , como as características de uso da aplicação, se a aplicação deverá rodar on premise ou em cloud, se há orçamento para comprar ferramentas adicionais, etc. Trataremos sobre esses pontos mais adiante.
Antes de continuar, um pouco de terminologia do MongoDB para evitar confusão. A tabela abaixo apresenta os nomes usados pelos objetos no MongoDB e seus equivalentes em SQL:
| MongoDB | SQL |
| Collection | Tabela |
| Documento | Linha |
| Campo | Coluna |
Analisando sua aplicação
O primeiro ponto que deve ser visto antes de definir qual (ou quais) banco de dados usar é a modelagem de dados a ser usada pela aplicação. O MongoDB, assim como a grande maioria dos bancos de dados de documentos, pede que suas collections sejam modeladas de forma a minimizar as quantidade de joins. Apesar de o MongoDB possuir o comando $lookup, que possui funcionalidade semelhante ao LEFT JOIN do padrão SQL, ele não é tão poderoso quanto aos diversos tipos de joins disponíveis em bancos relacionais, ou seja, geralmente é mais vantajoso construir aplicações com muitos relatórios, ou com relatórios que envolvem muitas tabelas, em bancos SQL.
Por outro lado, aplicações que tenham alto volume de tráfego e pouca ou nenhuma transação longa, como logs, registros de leitura de email, dados de chat e de cliques de usuário, etc., são mais otimizados em bancos de dados NoSQL.
Outros tipos de aplicação que aproveitam bem as características do MongoDB são as que possuem muitos dados opcionais, como por exemplo num e-commerce, onde alguns produtos podem ter informações adicionais como cor, tamanho, peso, voltagem, etc. O Mongo também é muito útil em aplicações que recebem dados de terceiros em formato JSON ou XML ou quando recebem dados de diversos fornecedores distintos. Em ambos os casos, os dados podem ser facilmente convertidos para o formato do MongoDB (BSON) e consultados posteriormente.
E quando minha aplicação possui ambas características, ou seja, partes onde é melhor usar SQL e outras em que é melhor usar o MongoDB? Nesses casos, deve-se analisar a possibilidade de se usar os dois (seja no mesmo executável ou em módulos distintos). Se isso não for possível, deve-se escolher o banco de dados mais adequado para a maioria dos usuários na maioria do tempo.
Um exemplo de modelagem em MongoDB
Para modelar um cadastro de clientes com telefones e endereços, costuma-se usar uma estrutura de tabelas semelhante a esta:
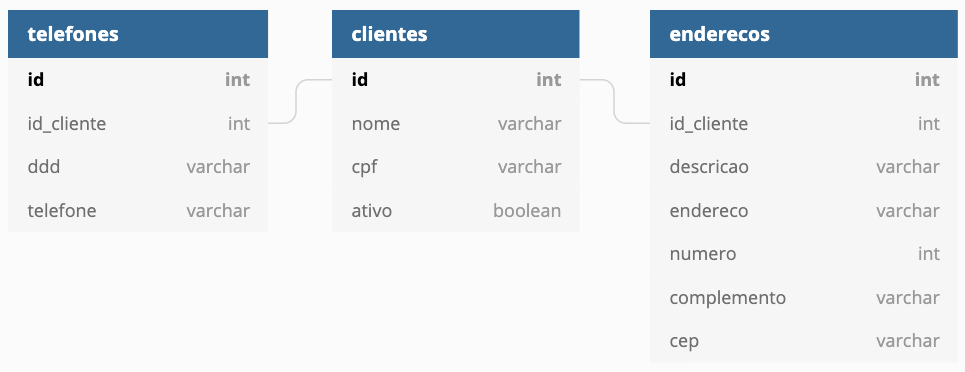
Para evitar a necessidade de joins no MongoDB, pode-se usar uma estrutura semelhante a essa:
{
"_id": ObjectId("507f191e810c19729de860ea"),
"nome": "José das Couves",
"cpf": "01234567890",
"ativo": 1,
"telefones": [
{ "ddd": "27", "telefone": "99999-8888" },
{ "ddd": "11", "telefone": "3333-4444" }
],
"enderecos": [
{
"descricao": "Casa",
"endereco": "Rua das Palmeiras",
"cep": "29030-010"
},
{
"descricao": "Trabalho",
"endereco": "Av. Brigadeiro Faria Lima",
"numero": 1234,
"complemento": "sala 1001",
"cep": "01452-920"
]
}
Um ponto interessante a observar é que um dos endereços não possui nem número e nem complemento. Isso permite economizar o espaço necessário para registrar o nome do campo e de um valor nulo. O MongoDB possui o valor null, mas na grande maioria dos casos é preferível simplesmente não registrar o campo no documento.
Apesar de ser possível criar documentos com vários níveis de hierarquia, lembre-se que não é uma boa ideia colocar tudo de um cliente em um só documento (ex: todo o histórico de vendas ou todos os dados de um chat dentro de um único documento de usuário, por exemplo), tanto por conta de limite de tamanho de documento (no máximo 16 MB) quanto em relação a performance, que cai consideravelmente quando os documentos são muito extensos. No caso de um histórico de vendas, é melhor criar uma collection de vendas e incluir um campo fazendo referência ao _id da collection de Clientes.
Uma dica para ajudar a organizar as collections é seguir os conceitos de Aggregates do padrão DDD (Domain Driven Design). Todos os objetos do Aggregate (ex: Pedido e Item do Pedido) ficarão no mesmo documento, mas objetos de outros Aggregates (ex: Clientes) serão referenciados apenas pelo seu ID.
Infraestrutura do MongoDB
É possível hospedar bancos de dados MongoDB de duas formas: em uma estrutura própria (on premise ou em uma VM em cloud) ou através de um serviço gerenciado. Trataremos das vantagens e desvantagens de cada a seguir.
Instalar o MongoDB em uma estrutura própria permite controle total do gerenciamento do banco de dados, além de ter uma economia de custos, principalmente se forem usadas versões open source do banco. Essas vantagens têm um custo: o gerenciamento de cluster e de backup fica por sua própria conta. Além disso, o MongoDB Community não possui uma boa ferramenta de backup, sendo necessário adquirir ferramentas adicionais como o MongoDB Cloud Manager (que apesar do nome, roda na sua própria estrutura) ou usar o Percona Server for MongoDB, que possui funcionalidades adicionais para backup, auditoria, etc., mas nem sempre são 100% compatíveis com o MongoDB padrão.
Caso sua infraestrutura já esteja rodando em cloud (na AWS, Azure ou Google Cloud), é possível usar as versões gerenciadas do MongoDB através do MongoDB Atlas. Com ele, você elimina a necessidade de gerenciar clusters, backups e upgrades manualmente, além de ter acesso a todas as funcionalidades do MongoDB Enterprise. Por outro lado, além do custo da própria solução, há também o custo de tráfego entre a conta da MongoDB e a da sua conta (que devem estar no mesmo provedor e região para evitar latência).
Existem fornecedores de soluções compatíveis com o MongoDB de terceiros, como o AWS DocumentDB e o Azure Cosmos DB, mas eles são bancos de dados distintos, apesar de terem compatibilidade com os drivers de acesso ao MongoDB.
Vantagens do MongoDB
O MongoDB possui várias funcionalidades muito úteis para as aplicações:
- escalabilidade: o MongoDB permite a criação de clusters sem dificuldades e sem a necessidade de ferramentas de terceiros. Além disso, se a aplicação utilizar o protocolo mongodb+srv://, não é necessário informar a aplicação sobre a inclusão ou remoção de nodes no cluster. Também é possível configurar a aplicação para priorizar as consultas de dados através das réplicas de leitura, retirando esse peso do node de escrita.
- replicação de dados: por padrão, todos os nodes de um cluster possuem todos os dados dos databases, evitando a perda de dados no caso de falha em um dos nodes.
- schema flexível: permite que documentos distintos tenham campos diferentes, evitando a necessidade de criação de campos com dados nulos na maioria dos registros.
- suporte a JSON: permite o armazenamento de dados vindos de uma API um de um arquivo JSON ou XML (ex: arquivos de NF-e) de forma fácil, permitindo consultas de forma bem mais fácil do que seria ao usar SQL, por exemplo.
Limitações do MongoDB
Apesar de o MongoDB ser uma ferramenta bastante poderosa, ele ainda não possui algumas funcionalidades muito importantes que já vêm por padrão na grande maioria dos bancos de dados relacionais. Vamos a elas:
- segurança: por padrão o MongoDB vem com o módulo de autenticação desabilitado. Se ele não for habilitado, o banco de dados passa a ficar vulnerável a erros humanos (excluir uma collection sem querer, por exemplo) e a ataques (por exemplo, um ataque de ransomware que busque bancos de dados sem senha e embaralhe os dados, exigindo pagamento para que possam ser recuperados, geralmente em criptomoedas para evitar o rastreamento).
- backup: o MongoDB nativamente não possui um gerenciador de backups decente. O mongodump, além de não permitir backups incrementais, tem problemas na exportação de collections muito grandes. Para resolver o problema, é necessário comprar o MongoDB Cloud Manager, migrar o banco de dados para a nuvem usando o MongoDB Atlas ou recorrer a ferramentas de terceiros, como o Percona Backup for MongoDB (gratuito). Com essas ferramentas, além do backup incremental, permitem fazer restauração de dados point-in-time (ex: restaurar os dados como estavam ontem às 13:45), muito útil quando uma operação é feita por engano (eu ouvi update sem where ? 😱).
- particionamento de collections: a grande maioria dos bancos de dados relacionais (MySQL, PostgreSQL, Oracle, etc) permite que suas tabelas sejam particionadas para otimizar a consulta em grandes volumes de dados. O MongoDB não possui essa funcionalidade, permitindo apenas sharding, que será explicado logo abaixo.
- sharding: é uma modalidade de particionamento em que cada partição fica em um cluster separado. Como cada cluster MongoDB requer no mínimo 3 máquinas, para se ter 2 shards são necessários pelo menos 6 hosts. Isso pode encarecer muito a operação, especialmente se ela estiver em cloud.
- validação de dados: o MongoDB não possui nenhum tipo de validação dos dados recebidos pela aplicação, ao contrário do SQL, que possui tipos de dados fixos, check constraints e triggers. Essa ausência permite que os documentos estejam em um formato inválido pela aplicação (ex: tipos de dados diferentes e valores inválidos em um campo), o que pode fazer que determinado documento não seja encontrado pela aplicação. Se, por exemplo, a aplicação espera que o campo “codigo” seja uma
stringe alguém insere manualmente comoint, umfind()pela string daquele número não retornará dados. - gerenciamento de collections: o MongoDB possui a característica de criar uma nova collection no caso de se fazer um insert em um nome de collection que não existe. Isso facilita a criação de novas collections, mas pode acontecer de haver um erro de digitação (ex: informar a collection
transactionsendo que o nome correto étransactions) e os dados serem gravados no lugar errado. É possível restringir o acesso do usuário para impedir que ele crie novas collections, mas isso também bloqueia a criação legítima de novas collections. - views e views materializadas: o MongoDB não possui suporte a views ou a views materializadas. A própria aplicação deverá ser responsável por simular a funcionalidade de uma view materializada.
- limites para ordenação: ao contrário dos bancos de dados SQL, o MongoDB não faz ordenação em disco caso não haja memória suficiente para ordenar um result set. Além disso, por padrão o Mongo limita uma operação de sort a 32 MB, ou seja, ordenar um conjunto grande de dados irá causar erro de execução, mesmo que se use
limit()para reduzir a quantidade de dados recebidos. A solução para esse problema é criar um índice com os mesmos campos encontrados no comandosort(), mas isso aumenta o consumo de espaço em disco e causa um certo aumento no tempo necessário para fazer insert/update/delete. - limites para criação/exclusão de índices: até antes da versão 4.2 do MongoDB, a criação de índices bloqueava a execução de outras operações na collection, a não ser que se especificasse o parâmetro
background: true. Outra limitação é que, ao deletar um índice, o banco de dados mata todas as sessões que estejam usando o índice no momento da execução do comando, ou seja, o DBA tem que esperar um momento em que ninguém esteja usando a collection para poder deletar o índice. - linguagem de query complexa: a linguagem de query do MongoDB é mais complexa do que o SQL, tanto por não ser tão difundida quanto por ter uma legibilidade menor (em muitos casos é questão de gosto pessoal, mas pode ser uma barreira para quem não está acostumado com o padrão JSON). Veja abaixo um exemplo em SQL e seu equivalente em MongoDB:
SELECT nome, cpf FROM clientes WHERE data_criacao >= date '2020-01-15' AND sexo = 'M' ORDER BY nome DESC
Exemplo de query em SQL
db.clientes.find({
"data_criacao": { $gte: new ISODate("2020-01-15") },
"sexo": "M"
}, {
"_id": 0,
"nome": 1,
"cpf": 1
}).sort({ "nome": -1 })
Exemplo de query em MongoDB
Conclusão
O MongoDB pode ser usado em uma grande variedade de aplicações, mas seus prós e contras devem ser levados em consideração antes de iniciar o projeto, especialmente se a modelagem de dados consegue ser encaixada tanto num modelo relacional quanto no MongoDB (com pouca ou nenhuma variação nas colunas entre os documentos).
Além das questões técnicas, deve ser levado em conta o conhecimento de cada tecnologia tanto por parte dos desenvolvedores quanto da equipe que irá administrar o banco de dados (DBAs, analistas de infraestrutura, etc) e a disponibilidade para estudar uma tecnologia nova e aplicá-la na operação da empresa. Também é necessário analisar o orçamento disponível para a operação, seja para a aquisição de hardware (on premise) ou para uso em cloud (instalando em máquinas virtuais ou como DBaaS, usando o serviço MongoDB Atlas).